

中国科大数据科学家校友研究

本文献给那些即将迈入职场的中国科学技术大学毕业生

背景:数据是现代经济中最有价值的资源,甚至有人把它称为“新石油”。如何处理数据是企业增长和成功的一个主要决定因素。许多企业正在对其管理层进行结构性改革,增加首席数据官(CDO)一职。下图展现了近年来CDO职位的增长速度。

图片来源见水印
中国科大新创校友基金会(简称:新创基金会)根据LinkedIn数据,综合北美校友实地调研,针对中国科大Data Scientist行业校友进行分析,希望为有志于成为数据科学家的年轻校友提供帮助和启发。本研究涉及Data Scientist行业校友的公司分布、地区分布、专业背景与技能分布等。
本研究也邀请了多位美中两国的Data Scientist校友,对成为数据科学家需要做哪些准备、必备的素质与技能、职业发展途径等方面与校友分享。
Data Scientist校友公司分布
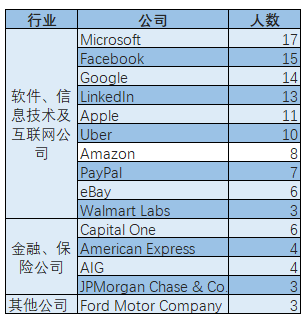
综合基金会数据中心与LinkedIn数据,新创基金会了解到Data Scientist校友在工业界的就职主要为软件、信息技术及互联网公司、金融公司、保险公司。
截至2018年9月19日,根据LinkedIn数据,中国科大Data Scientist校友有471人,校友数最多的软件、信息技术及互联网公司为Microsoft(17人)、Facebook(15人)、Google(14人)校友数最多的金融公司为Capital One(6人)。
Data Scientist校友的地区分布
截至2018年9月19日,根据LinkedIn数据,中国科大Data Scientist校友有471人,占LinkedIn上校友总数的1.28%。Data Scientist行业校友集中的国家与地区详见下表。
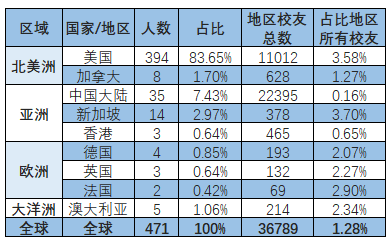
特别说明:鉴于LinkedIn注册的中国科大校友并不全面,或并未完整标注(毕业于中国科大或职业信息),诸多校友因未使用LinkedIn而未计入此次研究。故实际Data Scientist校友人数将远高于471人。此前的新创基金会分析表明:中国科大美国校友人数为LinkedIn注册人数的两倍以上。因中国科大Data Scientist绝大多数在北美,推测实际中国科大在美Data Scientist应在1000人以上。
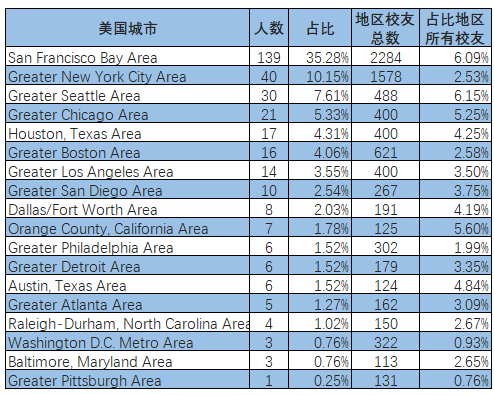
美国:根据LinkedIn数据,中国科大校友在美国的Data Scientist校友有394人,其中超过1/3的校友在硅谷(322人),超过10%的校友在大纽约地区,超过7%的校友在大西雅图地区。
新创基金会汇总了LinkedIn上校友人数100位以上城市Data Scientist校友的分布情况,详见下表:
中国:根据LinkedIn数据,在中国仅有38位注册校友为Data Scientist。大量在中国工作校友未注册LinkedIn,故该数据存在较大的偏差。从已有数据分析可得,中国Data Scientist校友主要分布在上海(13人,占比34.21%)与北京(8人,占比21.05%),其次分布在杭州(3人)、香港(3人)、深圳(2人)。
Data Scientist校友专业背景分析
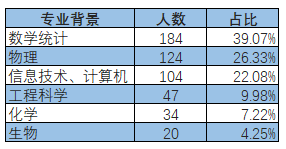
在LinkedIn上以Data Scientist为关键词进行搜索,将对曾经或现在从事数据科学家的校友进行学科背景分析,希望展现出成为数据科学家需要怎样的学科背景,希望为有志进入该行业的年轻校友产生一定的帮助和启发。
若校友拥有多个专业背景,则多个专业背景重复统计。Data Scientist校友专业背景具体分布如下:
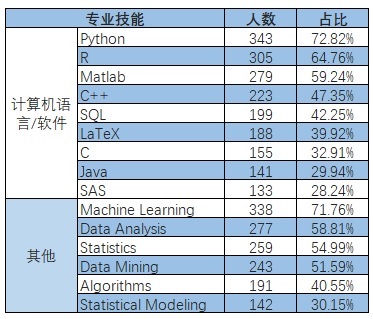
Data Scientist校友专业技能
根据LinkedIn数据,排在前面15名的Data Scientist专业技能其中9项为计算机语言或软件。排在第一的计算机语言是Python,超过70%的Data Scientist校友具备该专业技能;另一项超过70%的Data Scientist校友具备专业技能为Machine Learning。
数据科学家:科大人教你入门
中国科大新创校友基金会向多位Data Scientist校友发出调查问卷。他们系统解析了中国科大理工科学子成为Data Scientist所需做的准备具备的素质、技能、罗列了参考书甚至在线学习渠道。我们对校友反馈做了初步归纳。
一、成为Data Scientist 需要做什么准备?有哪些必备技能和素质?
(1)编程技能:
Python, R, SQL的编程经验
有能力单独做ETL pipeline (extract data, transform data, load data)
常用的模型库和框架要熟练
深度学习框架,如Tensorflow, Pytorch, Caffe, Keras等
常用的机器(深度)学习模型要熟练(包括原理和实践)
(2)数学统计技能
有较好的数学、统计基础,修过若干相关的数学课程或自学过相关的数学学科。
(3)沟通技能
能和business user很好的沟通
向管理层和各种非同行用日常语言而不是技术性语言解释自己的工作
有一定的case study的能力,有应用模型并能从商业价值的角度阐述的能力
热词、关键词张口就来,会的不会的都有过经验;胆大心细脸皮厚,厚到被人拆穿还有话应付圆场(注意本建议来自匿名校友,他语带调侃。)
(4)解决问题能力
解决问题和发现问题的能力,一定的独立性,要有全局观。
解决实际问题的能力,可以通过找一些real world projects来练手,获得对开放式的和没有明确定义的问题的思考和应对。
一位校友概括为:统计、数据挖掘、机器学习方面的理论基础,加上一定的编程实现能力,能充分利用开源社区的工具提高生产力。另一校友提到的略微不同,他指出: R or Matlab 用来做探索性数据分析,要学会用 java/ C++等语言 来对基于hadoop/spark集群来做大规模计算。还需要在实战中积累比较丰富的数据分析经验。
定义并解决新问题的能力
(5)新技术进展跟进
最新的深度学习进展要感兴趣和多跟上
要能尽量深的研究模型和跟上最新的学术进展
二、成为Data Scientist的必备书单?
(1)基础知识:算法,机器学习,数据库,数据挖掘,概率论、数理统计,随机过程,数值计算,运筹学。
(2)进阶知识:自然语言处理,深度学习,贝叶斯统计,时间序列,随机采样,非参数统计,稳健统计,拓扑和几何的基础知识。
(3)推荐书单:
《Pattern Recognition and Machine Learning》M.Bishop
《Machine Learning课程讲义》Andrew Ng
《机器学习》周志华:百度数据科学家董维山强调:我推荐周志华教授《机器学习》(俗称“西瓜书”),但他告知:准备应为多方面的,概括为专业知识+实践经验,同时保持对新技术的不断学习也非常重要。)
《时间序列:非参数和参数方法》范建清
《Categorical Data Analysis》Alan Agresti
《The Element of Statistical Learning》 T. Hastie / R. Tibshirani / J.H.Friedman
《统计学习方法》李航
《Statistical Inference》Casella & Berger
《All of Statistics A Concise Course in Statistical Inference》Larry Wasserman
(4)学术文章
(5)在线学习渠道
Coursera:Python、R、Machine Learning等知识的学习
LeetCode:学习算法和数据库
Udacity:模型学习
关于准备,王倪提醒:Data Scientist就是懂Computer Science的Statistician, 或是了解statistics的computer scientist。 既然有个scientist在里头,肯定是需要对整体的学科脉络了解很清楚,对于很多常用的benchmark algorithm和各种方法论,需要知其然而知其所以然。需要对cs, statistics里头的algorithm, large scale computing network, statistical methodology 以及近年来的deep learning都要掌握
三、数据科学家的职业发展途径会是怎样的?
不同公司对Data Scientist定义还是差别比较大的。大体上有两个方向:(1)偏“Scientist”,工作重点是modeling,research;(2)偏“data”,工作重点是提取数据,然后做数据的分析。
技术岗位通常是:Data Scientist->Senior Data Scientist->Principle Data Scientist ->Chief Data Scientist
管理岗位:技术岗位到某个级别之后可以开始做manager,之后是以design跟把握大方向为主
“对这个行业上升期的估计,数据科学家会不会被AI替代?”:董维山与王倪博士还回答了本追加问题。
董维山认为:很多企业已经设立了首席数据官这样的职位。数据对于企业、政府的价值不言而喻,重要性只会越来越高,我坚信能深入理解业务同时对数据价值有深刻洞察的数据科学家会有极大的发展空间。鉴于对优秀数据科学家的极高要求,我认为当前的AI发展还远不足以取代这种角色。
王倪认为:AI会能够大大提高数据科学家的工作效率,一些重复性的或者trivial的工作,更多的会被AI取代。然后data scientist的时间更多的可以解放出来,做数据产品的顶层设计,或者做一些开创性的研究工作。
四、其他想和即将进入这个行业的科大校友分享的?
(1)建议想好了Machine Learning Engineer或者Data Scientist哪种更适合自己。喜欢编程不很喜欢太多统计的更适合Machine Learning Engineer,工作机会更多。
(2)科大校友做data science有明显优势:无论什么专业,数学和编程都有过很多学习和训练,逻辑思维好,科研经历对做data science非常有帮助。需要补足的是解决实际问题的能力和沟通能力。
(3)不管job title是什么,作为一个在科技公司工作的Economist,需要business和statistics的双重技能。科大校友往往不缺第二个技能,但在第一个技能上需要加强。另外,科大校友需要加强自己的沟通能力。即使科大的理工类课程,也应该鼓励教授多给一些学生上去做presentation的机会,相信这点对培养科学家也是非常有用的。
(4)科大有很多做的非常出色的数据分析方向的大牛。我个人比较喜欢的入行者是有好奇心的,并且有勇气去参加各种数据建模竞赛,而且能够从中不断提高以及不断挑战和证明自己分析能力的。这个行业发展很迅速,需要不间断的学习。
致谢:本研究得到多位校友的指导与建议,新创基金会特在此对他们表示感谢:吕振宇(9517,Google)、王倪(96少,量化派联合创始人兼COO,曾任Google数据科学家)、杨锐(0304,Teradata)、董维山(0011,百度)、余浩(0101,一点资讯)、师振宇(true[X])、黄溯(0017、Amazon公司,曾任Neustar数据科学家)、王道艳(9922,Amazon,曾任Zillow数据科学家)、姚婕妤(1220,Amazon)、匿名校友(某石油公司数据科学家)。杨婧对调查问卷问题给出了建议与补充。
缘起:本研究源自新创基金会研究部2017年2月在芝加哥与师振宇、陈嘉桐(0904)、2018年5-6月在波士顿与杨婧(0708)的讨论与启发。
研究机构:中国科学技术大学新创校友基金会研究部。
研究作者:李惠玉(9507)和刘志峰(9500)。李惠玉(9507),美国加州理工学院地球化学硕士,新创基金会研究部(2009-2010,2016.5至今);刘志峰(9500),2007年获加拿大滑铁卢大学生物信息学理学硕士。2006年12月起供职于新创基金会。
2018-09-19 京公网安备 11010802035836号
京公网安备 11010802035836号